

どうも皆さま、ここ数週ほど間が空いてしまいましたがお久しぶりです。ここのところはブログ以外の面々で多忙であり、また最近課題となっている問題に関して取り組んでいたため解説記事を掲載できませんでした。
その取り組んでいた課題というのは「レース分析」についてです。最近になって「レース分析」は「カイ二乗検定」による判定を加えたことで複勝数に差が明確な差があるか分かるようになり、正確性が向上しました。一方で、分析を進めていくうちにほとんどの項目で「カイ二乗検定」が「0.05超過」、つまり”明確な差がない”という結果になることが分かり”「複勝率」による「レース分析」にあまり意味がない”という見解になりつつあります。
よって、「新たなレース分析」の方法を確立する必要が出てきたため、その方法を模索していました。幸いにも「騎手データ」の数が相当な量になってきたため(現在、過去5年間で行われた芝レースに出走した馬の騎乗データの内の約99%を収集完了)、そのデータを活用して分析する方法を検討した結果、「複数の同条件」における「レースタイム」を抽出し、その抽出した「レースタイム群」をさらに「T検定」による判定によって選別し、最終的に抽出された「レースタイム群」の平均を比較することで優劣を判断するという方法に至りました。
今回はその「新たなレース分析」、名付けて「抽出レースタイム選別平均比較」について解説をしていきます。
始めに:今までの「レース分析」の問題点
「レースタイム抽出平均比較」について解説する前に、先に今までの「レース分析」の問題点に関して改めて説明していきます。
1.「カイ二乗検定」により大半で”明確な差がない”
まず冒頭で説明したように、「カイ二乗検定」による判定を取り入れたことでほとんどの場合で項目ごとの「複勝数」の差が”誤差の範囲での差”でしかないこと分かっており、最大の問題点になっています。”明確な差”が発生する項目があったとしても大抵は「オッズ」のデータであり、それならば人気順に従って選べばいいという話になるので分析する意味がありません。
2.サンプル数が比較的少量
今まで触れてこなかった点としてサンプル数が比較的少量という点もありました。過去5年間に行われた同一レースのみを参照する場合、最多でも90頭分のデータしか収集できないので統計分析としては少量となってしまいます。その欠点を補うために「カイ二乗検定」を導入した面もありますが、むしろより露呈させているのかなと感じています。
3.順位に焦点を当てた分析法
今までの分析は「複勝率」を重視していましたが、つまりは「複勝数」=「着順3位以内」の割合に着目しているということです。これは「順位」を参照しているので結局は正確性に欠けています。「順位」は実際の差の大小に関係なく上下の差が「1」の差になります。例え「3位」と「4位」の走破タイム差が「0.1秒未満」でも「2.0秒以上」でもその順位の差は何が有ろうと「1位差」なので問題なのです。
以上の主に3つの点が課題でした。最大の問題は「カイ二乗検定」を導入したことによりほとんどの場合において「実値」と「期待値」に明確な差がないことが分かったため、結果として実質的な複勝率が「全体の複勝数/全体の出走数」になってしまうことです。他二つの問題も正確性を考える上で改善する必要があります。
解決案:「走破タイム」をベースにした分析に変える
その解決方法として今までの「複勝率」に着目した分析方法から「タイム指数」と同じように「走破タイム」を活用した分析に切り替えることにしました。また、「分析対象のレース」を分析するレースと同じ競馬場かつ同じコース距離のレースまで拡大し、サンプル数を増やします。
メリット
・実値と期待値の誤差判定が不要=「カイ二乗検定」が不要。
・順位に依らないためより数値的な分析になる。
・サンプル数がほぼ確実に最少でも100を超える。
以上の3点が挙げられます。
デメリット
・過去の分析よりも調べられるデータ項目が少なくなる。(1走前レースや2走前レースなどのデータを収集して分析することが難しく当日レースに関わるデータしか扱えないです)
・よりマクロ的な分析になるため、分析結果が個々の馬の実績を大きく無視してしまう可能性が高くなる。
以上、2点が挙げれます。
結論から言うと、デメリットの2点はサンプル数が増加したことによる影響なので致し方無いことだと考えています。分析できるデータ項目が減る一方でサンプル数が増加するため信頼性には問題がなく、個々の馬の実績を無視してしまう点はむしろ過去の実績に縛られずより客観性が高い比較が行えるとも言えます。
よって総合的に判断したうえで同条件の競馬場・コース距離で走った馬の「走破タイム」を様々な項目に分けて分析し、それらを基に比較評価を行うという方法に至りました。
それでは具体的にどのような方法で行うのかを説明していきます。
抽出レースタイム選別平均比較法
まず、大まかな流れとしては以下の大きく分けて6ステップになります。
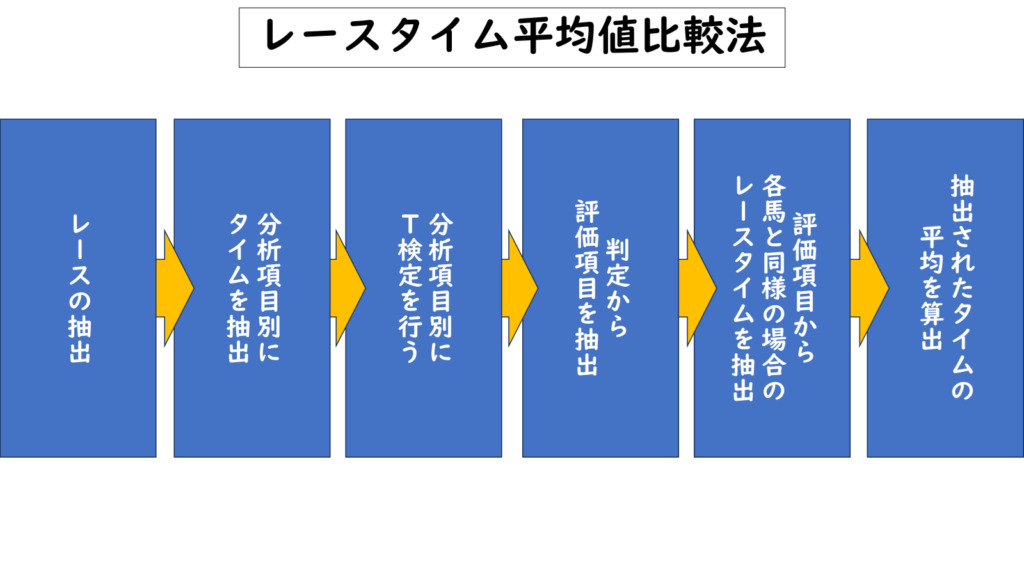
1.レースの抽出
まずは分析したいレースと同競馬場・同コース距離のレースを抽出します。私の場合は騎手の傾向を分析するために収集した過去5年間にレースへ出走した馬のデータ群から抽出します。
例えば、「アイビスサマーダッシュ(GIII)」の場合は「新潟芝1000m」のレースを抽出します。その場合、少なくとも該当するレースに出走した馬は1750頭以上になるのでサンプル数としても問題ありません。
「タイム指数」と違い「馬場」を抽出する条件として加えていませんが、それは過去5年間のレース結果から抽出したとしても「重馬場」・「不良馬場」で行われたレースの数が圧倒的に少ないからです。「馬場」も考慮して抽出を行うとサンプル数が不足してしまう可能性が極めて高いのです。加えて、当日の馬場状況はその日になってみないと分からないため事前予測が困難になってしまいます。そのため、「タイム指数」と違い「馬場」を抽出する条件に加えていないのです。
2.分析項目別にレースタイムを抽出
次にそれぞれのカテゴリーごとに分析項目別にレースタイムを抽出を行います。
カテゴリーとしては基本的に
・「枠番」
・「斤量」
・「オッズ」
・「馬体重」
・「馬体重増減率」
・「斤量馬体重比」
の6つに分けられます。
カテゴリー解説:斤量
「斤量」は過去5年間のレースに出走した馬のデータ全体の度数を鑑みて、最小階級を「51㎏以下」・最大階級を「57㎏超過」とした上でその他の階級は「階級の幅」=「1kg」とした「階級」に分けて抽出を行います。
よって階級は
・「51㎏以下」
・「51㎏超過かつ52㎏以下」
・「52㎏超過かつ53㎏以下」
・「53㎏超過かつ54㎏以下」
・「54㎏超過かつ55㎏以下」
・「55㎏超過かつ56㎏以下」
・「56㎏超過かつ57㎏以下」
・「57㎏超過」
以上8階級に分けられます。
カテゴリー解説:オッズ
「オッズ」は過去5年間のレースに出走した馬のデータ全体の百分位数の「10%刻み」に該当する値と単勝オッズの理論上の最低値「0.8倍」を「階級」として抽出します。
よって階級は
・「0.8倍以上かつ3.7倍未満」
・「3.7倍以上かつ5.7倍未満」
・「5.7倍以上かつ8.3倍未満」
・「8.3倍以上かつ12.6倍未満」
・「12.6倍以上かつ18.3倍未満」
・「18.3倍以上かつ27.4倍未満」
・「27.4倍以上かつ42.9倍未満」
・「42.9倍以上かつ71.9倍未満」
・「71.9倍以上かつ141.4倍未満」
・「141.4倍以上」
以上10階級に分けられます。
カテゴリー解説:「馬体重」・「馬体重増減率」・「斤量馬体重比」
「馬体重」・「馬体重増減率」・「斤量馬体重比」は「階級の幅」を、「過去5年間のレースに出走した馬のデータ全体から算出されたそれぞれのカテゴリーの標準偏差」を参考とした値にしています。
基本的に
「馬体重・階級の幅」=「30㎏」
「馬体重増減率・階級の幅」=「1.2%」
「斤量馬体重比・階級の幅」=「1.0%」
とそれぞれ設定しています。
3.分析項目別にT検定による判定
それではここからがこの分析の醍醐味です。上で各カテゴリーごとに階級のレースタイム群が出来ましたが、それらカテゴリーごとにレースタイム群同士のT検定を行います。例えば、「アイビスサマーダッシュ(GIII)」を例に挙げると枠番は以下のような表にまとまります。
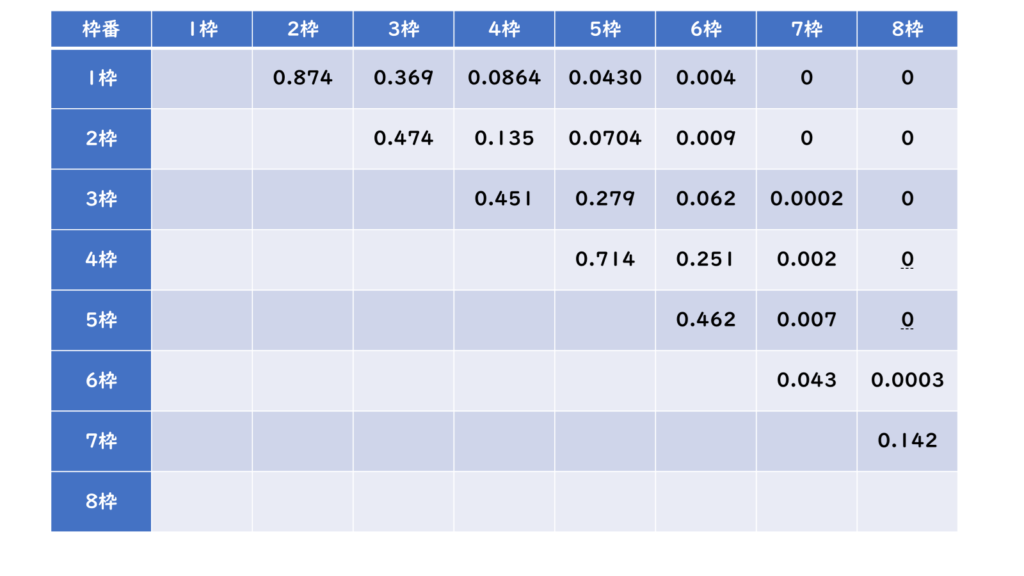
このように各枠ごとのレースタイム群をそれぞれの組み合わせでT検定を行い判定します。(実際にはそれぞれの組み合わせで分散が一致しているかも判定するので事前にF検定も行っています)
判定から評価項目を抽出
T検定よって判定されるのは、二つのデータ群の平均値に差が無く同様の母集団であるかです。値が「0.05超過」であれば同様の母集団であり、「0.05以下」であれば全く違うデータ群であることが分かります。先ほどの表を見てみると、1枠から4枠までは値が「0.05超過」であるため同じデータ群であることが分かりますが、7枠・8枠はそれより内枠のデータ群との判定が「0.05以下」であるため、違うデータ群であることが分かります。
このようにカテゴリー内で明確に他の項目と違うデータ群がある場合はこれらは差が出やすいカテゴリーと判断して評価項目にします。一方でカテゴリー内で明確に他の項目と違うデータ群が無い場合はそのカテゴリーを評価項目として扱わず、そのレースにおいて無視することにします。
例えば、「アイビスサマーダッシュ(GIII)」の場合と増減率は以下のような表にまとまります。
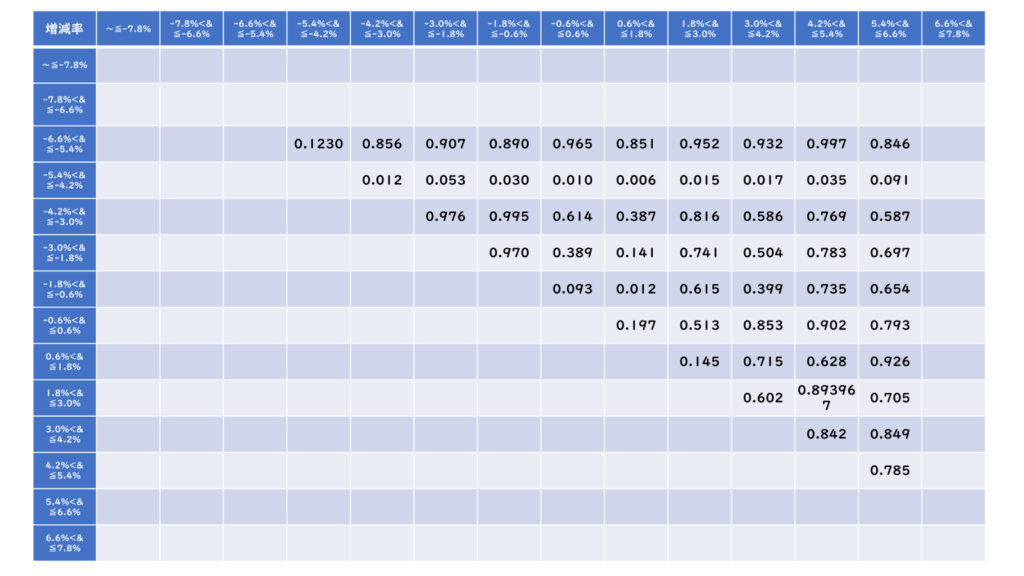
このようにほとんどの項目で「0.05超過」であるためカテゴリー全体でほぼ同じデータ群と言えます。この場合、階級の変化でタイム差が出ないため意味がないと判断しそのレースの評価においては評価項目として扱わないと判断します。
評価項目ごとに各馬と同様の場合のレースタイム群を抽出
さて、評価方法もここで大詰めになってきます。各カテゴリーごとT検定を行い評価項目が決定したならば、各馬ごとに評価項目内で同様の場合のレースタイム群を抽出します。
例えば、以下のような状況の場合を説明します。
競走馬A
・枠番:3枠
・斤量:56kg
・オッズ(単勝):8.2倍
・馬体重:486kg
・増減率:1.25%
・斤量馬体重比:約11.523%
この場合、それぞれの抽出されるレースタイム群は
競走馬Aの抽出レースタイム群
・枠番:「3枠」の場合のレースタイム群
・斤量:「55㎏超過かつ56kg以下」の場合のレースタイム群
・オッズ:「5.7倍以上かつ8.3倍未満」の場合のレースタイム群
・馬体重:「480㎏超過かつ510kg以下」の場合のレースタイム群
・増減率:「0.6%超過かつ1.8%以下」の場合のレースタイム群
・斤量馬体重比:「11.2%超過かつ12.2%以下」の場合のレースタイム群
以上、6つのレースタイム群が抽出されます。
しかし、T検定による判定を行うので6つ全てのデータを使うわけではありません。ここでは「枠番」と「増減率」に関してはT検定の結果から条件ごとに差がないため使わないという設定します。
よって実際に評価されるレースタイム群は、
・斤量:「55㎏超過かつ56kg以下」の場合のレースタイム群
・オッズ:「5.7倍以上かつ8.3倍未満」の場合のレースタイム群
・馬体重:「480㎏超過かつ510kg以下」の場合のレースタイム群
・斤量馬体重比:「11.2%超過かつ12.2%以下」の場合のレースタイム群
以上、4つのレースタイム群になります。
評価対象のレースタイム群の平均値を算出
最後に評価されるレースタイム群の平均値を算出して比較を行います。
上述の競走馬Aの場合は、
評価平均タイム=斤量:「55㎏超過かつ56kg以下」の場合
+オッズ:「5.7倍以上かつ8.3倍未満」の場合
+馬体重:「480㎏超過かつ510kg以下」の場合
+斤量馬体重比:「11.2%超過かつ12.2%以下」の場合
以上のようになります。
実際に「抽出レースタイム選別平均比較」で予測する
実際に今年開催された「アイビスサマーダッシュ(GIII)」の評価平均タイムをまとめてみました。
「アイビスサマーダッシュ(GIII)」の場合は、増減率のデータがT検定の判定により階級ごとに差がほぼないことが分かったため評価されるのは、枠番・斤量・オッズ(単勝)・馬体重・斤量馬体重比の5つのレースタイム群です。
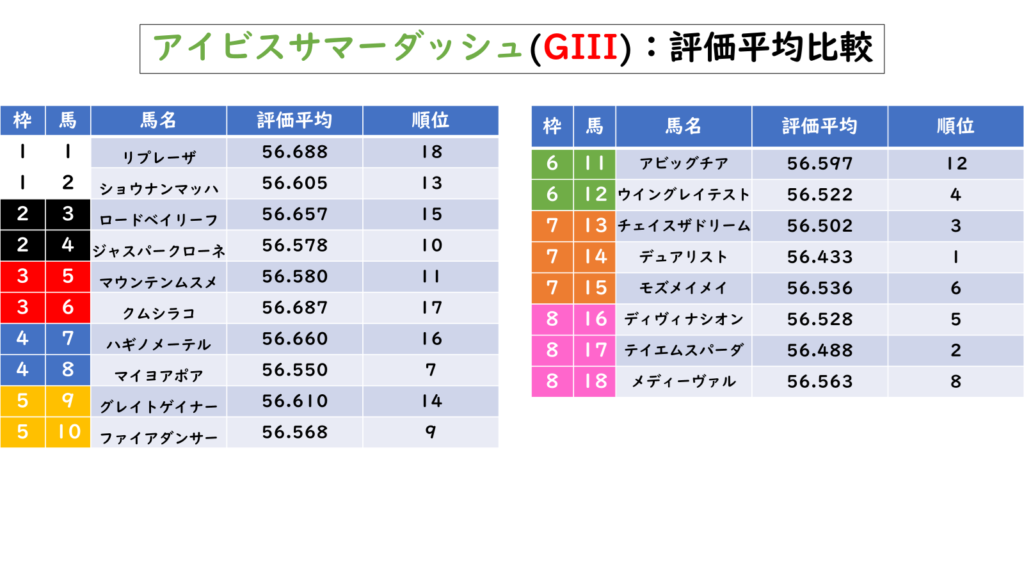
以上のようになります。実際の順位との比較は詳しく話しませんが、今までの分析以上に予測と一致していると感じています。基本的には予測順位6位までの評価なら3着以内に入る可能性が高いと考えられます。
札幌記念・CBC賞から新たな分析による記事になります
如何だったでしょうか。非常に複雑な過程を経て比較評価を行う上に、データが非常に多く求められる方法なので真似できる方は少ないと思われますが、こちらのブログでは毎週この分析方法による予測を行っていきますのでご期待ください。
次の土日の札幌記念・CBC賞からは新たな分析による解説を行いますので楽しみにしていてください。
今回の記事は以上になります。ご閲覧ありがとうございました!

